

Современные алгоритмы работы искусственного интеллекта основаны на методах анализа корреляций и статистических связей в больших данных. Когда машина принимает решение, она просматривает заложенную базу текстов, находит наиболее часто встречающиеся связи и на основании этого анализа выдаёт ответ.
Хорошей иллюстрацией этого является визуализация библиотеки RoBERTa, разработки Allen Institute of AI, опубликованная в середине 2019 г.
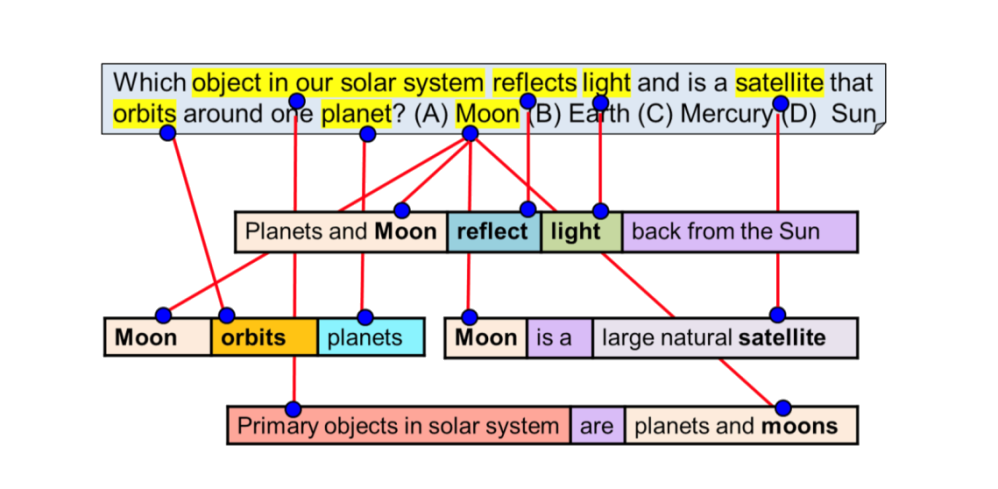
Подобные решения, являющиеся самыми передовыми, позволяют отвечать только на узкие вопросы, вроде тех, которые реализованы в голосовых помощниках в телефонах — Siri, Алиса, Google Assistant, Amazon Alexa.
Наиболее продвинутый показатель уровня понимания для ИИ-систем — метрика SuperGLUE была запущена DeepMind и Facebook в 2019 году для определения степени понимания текста машиной. Это короткий тест из восьми типовых вопросов на понимание смысла текста (предложений). Испытуемому надо прочесть описание ситуации и ответить на вопрос о том, как ее интерпретировать.
Сложность задачи примерно соответствует уровню начальных классов. Текущая точность — до 80%.

Новый конкурс Up Great направлен на создание новых подходов в ИИ, которые позволят машине разбираться и учитывать, как соотносятся причина и следствие. Такие подходы будут полезны и в обработке естественных языков, и во многих других областях применения ИИ.
Для реализации технологий понимания смысла текстов выбрана область образования, так как для образовательных текстов существуют наработанные методики сравнительно объективной оценки качества текста. Кроме того, обучение — социально значимая и нуждающаяся в инновациях индустрия.
В конкурсе будет создаваться технология, которая сможет находить смысловые ошибки в любых текстах и сообщать об этом в режиме реального времени:
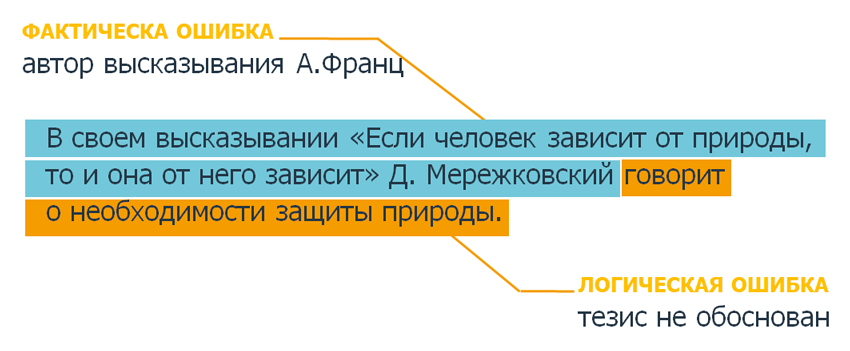


Конкурс проводится по тематике использования технологий машинного анализа текста для повышения качества и скорости выявления фактических и смысловых ошибок в академических эссе студентов, школьников и иных обучающихся. Технологии, развиваемые в рамках проведения конкурса, смогут стать ядром широкого спектра продуктов.
Обработка естественного языка (NLP, natural language processing) является динамично развивающейся областью искусственного интеллекта, находящейся в фокусе большого количества специалистов и при этом имеет достаточно низкий «порог входа»: для разработки NLP-решений специалисту не требуется значительных инвестиций в оборудование и фундаментальных научных знаний.
ГРАФИК КОНКУРСА
В ходе конкурса проводятся регулярные циклы испытаний. Каждый цикл состоит из отборочного этапа, квалификационных и финальных испытаний.
Испытания первого цикла прошли в период с октября по декабрь 2020 г.
Регистрация на второй цикл открыта.
Вопросы и ответы
Технологический конкурс Up Great ПРО//ЧТЕНИЕ объявлен в декабре 2019 года. Конкурс разделен на несколько циклов испытаний. Каждый цикл состоит из этапа приема заявок, квалификации, т.е. допуска к испытаниям, и непосредственно самих испытаний. Первый цикл планируется завершить уже к концу 2020 года.
Квалификация первого цикла конкурса пройдет с 1 октября по 2 ноября и будет общей для русскоязычных и англоязычных текстов. В этот период для получения допуска к испытаниям зарегистрированные участники должны будут скачать тексты тестовой выборки квалификации через API, разметить их без ошибок в синтаксисе и загрузить все файлы обратно.
9 ноября пройдут первые испытания конкурса для русскоязычных текстов. Задача испытаний – выявить в течение ограниченного времени (не более 30 секунд в среднем на одно эссе) и аннотировать все ошибки на уровне экспертов-преподавателей. 16 ноября состоятся испытания для англоязычных текстов.
Подведение итогов первого цикла конкурса запланировано на декабрь 2020 года.
Испытания будут повторяться регулярно до тех пор, пока не будет выявлен победитель, но не позднее декабря 2022 года. Прием заявок на квалификацию первого цикла завершится 29 октября, после чего стартует прием заявок на участие во втором цикле конкурса.Испытания пройдут в несколько этапов:
1. Технический. Участники подключаются к серверу, скачивают датасет, ищут ошибки и загружают обратно.
2. Основной. Участники получают новые сочинения, которые не публиковались ранее и которые не видели преподаватели. Они делают разметку и загружают обратно.
3. Проверка. Технический этап, в рамках которого техническая комиссия и судейская коллегия проверяют результаты работы команд, сами эссе и сочинения для объективного определения ошибок и уровня технологического барьера. Результаты экспертов автоматически сравниваются с решениями команд.
4. Объявление результатов.
Первые данные (эссе и сочинения) размещены в разделе Датасеты. Команды имеют право обучать свои решения на любых других данных, оценивается только конечный результат.
Оцениваться будет путем сравнения со средним количеством ошибок, которые живой эксперт-преподаватель способен найти в тех же документах в условиях ограниченного времени.
Команды подключаются к платформе по API, скачивают txt файлы с простым wiki- или markdown-подобным языком разметки, при помощи которого в тексте отмечают найденные ошибки. После этого отредактированный txt-файл загружается обратно по API и оценивается на платформе программным решением организаторов.
Процедура проведения испытаний прописана в техническом регламенте конкурса.Испытания конкурса будут повторяться регулярно до тех пор, пока не будет выявлен победитель, но не позднее декабря 2022 года. Это мы называем «циклами», каждый из которых состоит из квалификации и основных испытаний конкурса.
До 2 ноября проходит квалификация 1-го цикла конкурса.Да, мы создали Slack канал #proj_upgreat_readable в сообществе Open Data Science (ODS.ai).
Для тех, кто присоединяется к каналу в Slack необходимо обратить внимание на следующие моменты:
- для того чтобы вам дали доступ в этот канал необходимо пройти регистрацию на сайте ods.ai при этом при регистрации указать, что вы участник конкурса ПРО//ЧТЕНИЕ;
- после этого вам на почту придёт одобрение от администратора и при входе в Slack вы будете иметь доступ в сообщество opendatascience.slack.com, в котором и находится канал конкурса #proj_upgreat_readable
И вы всегда можете прислать ваш вопрос нам на почту ai@upgreat.one.
Во-первых, в 2021 году будет запущен краудсорс образовательных текстов с разметкой, который позволит кратно увеличить обучающую выборку.
Во-вторых, действительно, в рамках конкурса необходимо выявить более 100 типов ошибок, некоторые из которых будут встречаться в обучающей выборке редко, поэтому вне зависимости от усилий по расширению обучающей выборки, этого будет недостаточно.
Это означает, что решение задачи потребует творческого подхода и нахождения новых приемов и методов, которые позволят решить проблему недостатка данных: краулинг и обработка школьных сочинений из интернета; использование передовых методик few-shot learning; нахождение нетривиальных приемов и использования профессиональной экспертизы педагогов.
Конечно, такой подход усложняет решение задачи, однако конкурс продолжается более двух лет, а сложность задачи компенсируется размером призового фонда.